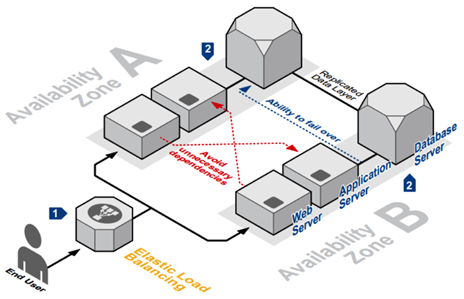
When deciding on system architecture for an enterprise, there are many factors to consider, such as performance, scalability, availability, reliability, cost, and operation. In particular, ensuring high availability for the system must always be focused on interruption or inactivity) to ensure business continuity. This is always shown with the businesses’ architectures, as every minute lost in system downtime can lead to a huge loss of enterprise’s revenue and reputation.
The glitch of the “giants.”
One of the issues discussed over the past month was an AWS service crash with Kinesis Data Streams errors, which lasted for hours, resulting in a wide range of services being affected; at a low level, the application is slow, there are cases where the application is completely paralyzed, the big names affected can be mentioned as 1Passwords, Adobe Spark, Autodesk, Coinbase, DataCamp, Flickr, Roku, The Washington Post …
Most recently, in the afternoon of December 14, 2020 (Vietnam time), Google services stopped working worldwide, with errors recorded, including Gmail, Google Calendar, YouTube, and a section of Google Search. The problem with Google affected a large number of Internet users globally. This is also the biggest Google crash in 2020.
It is easy to see that big names like Google or AWS are inevitable problems with the system; although the probability is extremely low and rare, the damage is not small.
So, what is High Availability (HA)?
High availability refers to the ability to avoid unplanned outages by eliminating single-point-of-failure (SPOF). High availability systems are understood as capable of continuing to function even when critical components fail, without interrupting service or losing data, and recovering seamlessly from failure. This is a measure of the hardware, operating system, middleware, and database management software reliability.
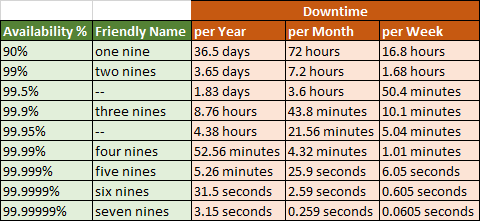
High availability is usually measured as a percentage of uptime. The amount of “nines” is often used to indicate high availability. For example, “four nines” indicates a system that is active 99.99% of the time, meaning it has only been down for 52.6 minutes for the whole year.
Most of the challenges with implementing high availability in an enterprise environment often involve product vendor(s) or application design – especially when implementing new products. Most small businesses don’t pay too much attention to the stringent requirements of 24/7 application support. The wrong decision-making can lead to a product architecture that is incompatible with the enterprise’s high availability solutions.

Elements for a complete High availability system
-
Redundancy: Ensuring that critical system components have another identical component with the same data can take over in case of failure.
-
Monitoring: Identifying problems in production systems that may disrupt or degrade service.
-
Failover: The ability to switch from an active system component to a redundant component in case of failure, imminent failure, degraded performance, or functionality.
-
Failback: The ability to switch back from a redundant component to the primary active component when it has recovered from failure.
AWS High Availability: Compute, Databases, and Storage
AWS helps you achieve high availability for cloud workloads across three different dimensions:
-
Compute Amazon EC2 and other services that let you provision computing resources provide high availability features such as load balancing, auto-scaling, and provisioning across Amazon Availability Zones (AZ), representing isolated parts of an Amazon data center.
-
Database: Amazon RDS and other managed SQL databases provide options for automatically deploying databases with a standby replica in a different AZ.
-
Storage: Amazon storage services, such as S3, EFS, and EBS, provide built-in high availability options. S3 and EFS automatically store data across different AZs, while EBS enables the deployment of snapshots to different AZs.
AWS High Availability for EC2 Instances
If you are running instances on Amazon EC2, Amazon provides several built-in capabilities to achieve high availability:
-
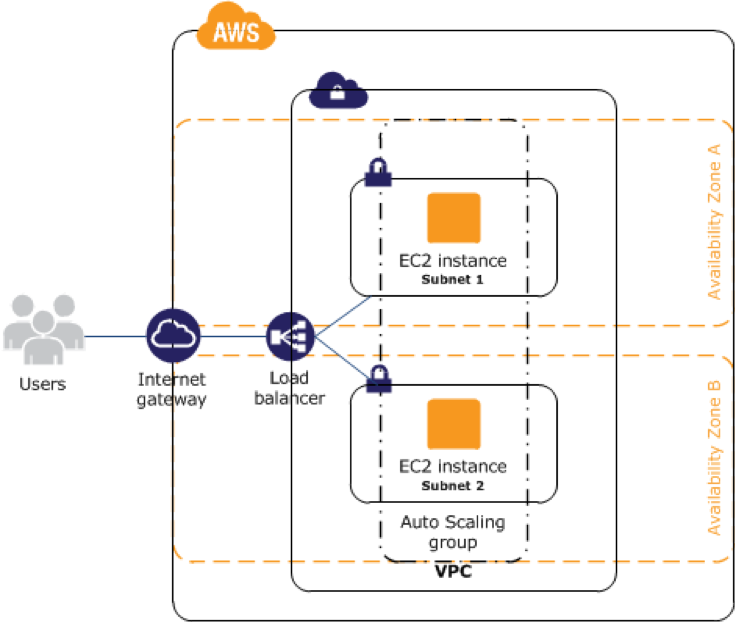
Elastic Load Balancing: Can launch several EC2 instances and distribute traffic between them.
-
Availability Zones: Can place instances in different AZs.
-
Auto Scaling: Detect when loads increase, and then dynamically add more instances.
These capabilities are illustrated in the diagram below. The Elastic Load Balancing distributes traffic between two or more EC2 instances, each of which can potentially be deployed in a separate subnet that resides in a separate Amazon Availability Zone. These instances can be part of an Auto-Scaling Group, with additional instances launched on-demand.
AWS High Availability for SQL Databases on Amazon RDS
- Availability Zone:
Each Availability Zone will have one or more data centers. The Availability Zone was created to ensure that all the essential components of AWS are always active and have sufficient emergency backup capacity.
Each Availability Zone operates independently but is still connected through its own high-speed fiber-optic network to facilitate data movement between Availability Zones within the same region.
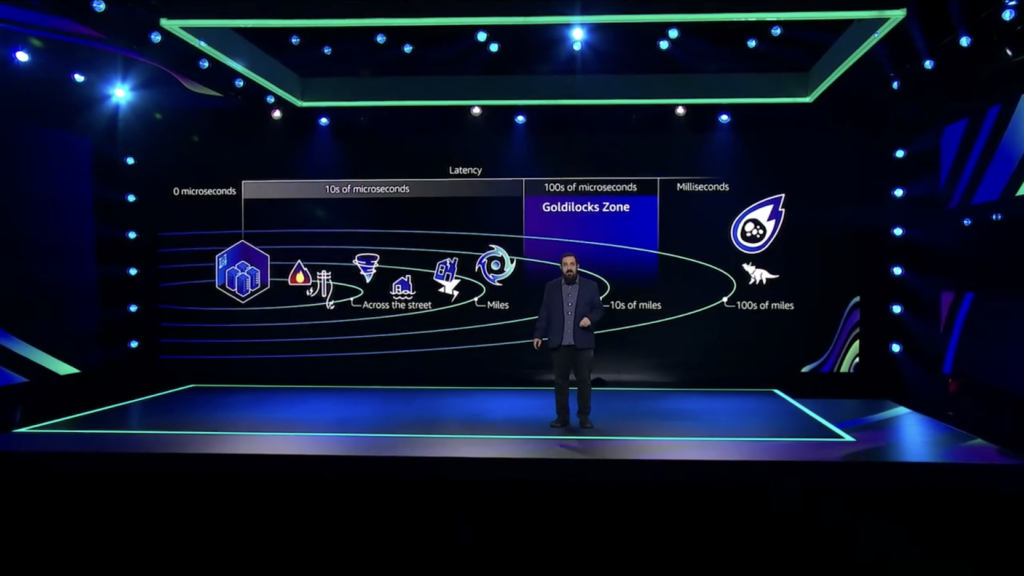
Each AZ is approximately 100km apart to ensure safety from disasters while retaining optimal latency.
- Region:
Each AWS Region concentrates at least 02 Availability Zones (North Virginia is currently the most AWS Availability Zones with 6 zones). In addition to backing up data between Availability Zones in the same region, users can also choose to back up data between different regions and use public or private networks to ensure that business operations always go smoothly and never interrupted.
Currently, AWS has about 77 Availability Zones spread over 24 different geographical regions. This number is expected to increase in the future to provide customers with richer service options.
AWS High Availability for SQL Databases on Amazon RDS
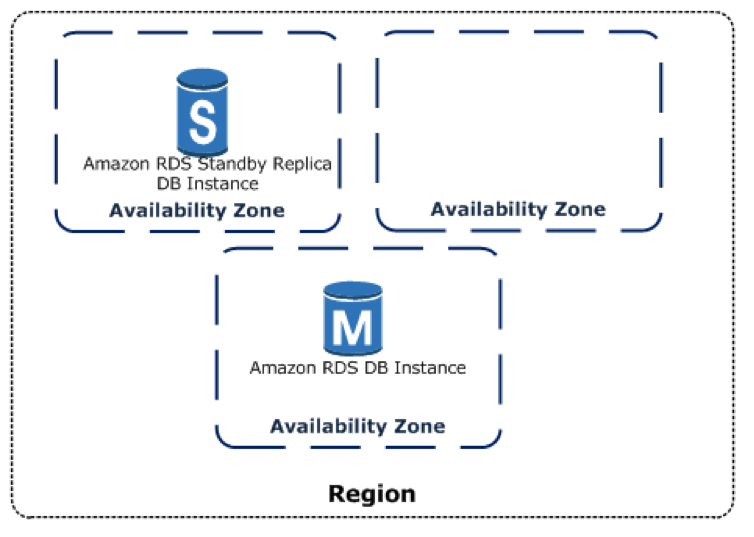
RDS provides high availability using Multi-Availability Zone (Multi-AZ) deployments. This means RDS automatically provisions a synchronous replica of the database in a different availability zone. When the main database instance goes down, users are redirected transparently to the other availability zone.
This provides two levels of redundancy:
- In case the active database fails, there is a standby replica ready to receive requests.
- In case of a disruption in the AZ, your main database instance runs in; there is a failover to another AZ.
The following diagram illustrates the Multi-AZ database deployment.
Note that Multi-AZ deployment is not supported for read-only instances, and you should use read replicas to enable high availability for those instances.
RDS provides the following capabilities per database type:
- For Oracle, PostgreSQL, MySQL, and MariaDB—high availability using Amazon Multi-AZ technology.
- For SQL Server—mirroring to another Availability Zone using Microsoft’s SQL Server Database Mirroring technology.
AWS High Availability for Storage Services
Here is a summary of the high availability capabilities Amazon offers for other popular storage services:
- Amazon S3:
S3 guarantees 99.999999999% (eleven 9’s) durability by redundantly storing objects on multiple devices across a minimum of three AZs in an Amazon S3 Region.
- Amazon EFS:
EFS guarantees up to 99.9% availability; otherwise, between 10-100% of the service fee is discounted. Every file system object is redundantly stored across multiple AZs.
- Amazon EBS:
EBS volumes are created in a specific AZ. You can make a volume available in another AZ, and it can then be attached to other instances in that same Availability Zone. To make a volume available outside the AZ or create redundancy, you can create a snapshot and restore it in another AZ within the same region. You can also copy snapshots to other AWS regions to create redundancy across Amazon Web Services data centers.
Conclusion
High availability focuses on ensuring the system can operate with the best performance even when part of the system fails, providing enormous benefits to the system that require high reliability.
About VTI Cloud
VTI Cloud is an Advanced Consulting Partner of AWS Vietnam with a team of over 50+ AWS certified solution engineers. With the desire to support customers in the journey of digital transformation and migration to the AWS cloud, VTI Cloud is proud to be a pioneer in consulting solutions, developing software, and deploying AWS infrastructure to customers in Vietnam and Japan.
Building safe, high-performance, flexible, and cost-effective architectures for customers is VTI Cloud’s leading mission in enterprise technology mission.